 I am a Machine Learning researcher and engineer, with a PhD focused in Computer Vision for learning video representations.
I am a Machine Learning researcher and engineer, with a PhD focused in Computer Vision for learning video representations.
I am a Machine Learning researcher and engineer, with a PhD focused in Computer Vision for learning video representations.
I am a Machine Learning researcher and engineer, with a PhD focused in Computer Vision for learning video representations.
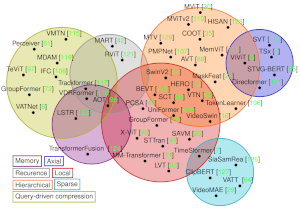
In this survey, we analyze the main contributions and trends of works leveraging Transformers to model video. Specifically, we delve into how videos are handled at the input level first. Then, we study the architectural changes made to deal with video more efficiently, reduce redundancy, re-introduce useful inductive biases, and...
Github tokens are used as a safety measure to connect to repos within your github account. It also allows you to push and pull without the need to write your password or storing it anywhere. Making it a commodity and also a safety feature.
This is actually very easy, but...