I-JEPA: Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
27 Sep 2024
.
paper-summary .
#paper-summary
Introduction
When LeCun first published his vision of how an embodied agent should function in the world I was excited. It is always nice to escape briefly into reading a little bit of theories and hypothesis on how things should work. It is important, I believe, to take a step back and make sure we’re still going in the direction we wish to follow, instead of banging our heads blindly against the next engeneering problem.
In his 60 page monograph titled “A Path Towards Autonomous Machine Intelligence”, LeCun introduces his ideas on what would be required to build an embodied agent into our world. One of the key cornerstones of this proposal are Joint Embedding Predictive Architectures (JEPA). The key idea here is the use of siamese networks (a couple of networks sharing architecture and potentially the weights) so that one receives an input and the other receives a slightly different input (either another part of the same input or a slightly modified version of it). The network is then trained so that the outputs from both of them should be predictible from one another (I recommend reading this blog post to get the general idea if you don’t feel like reading a 60 page monograph).
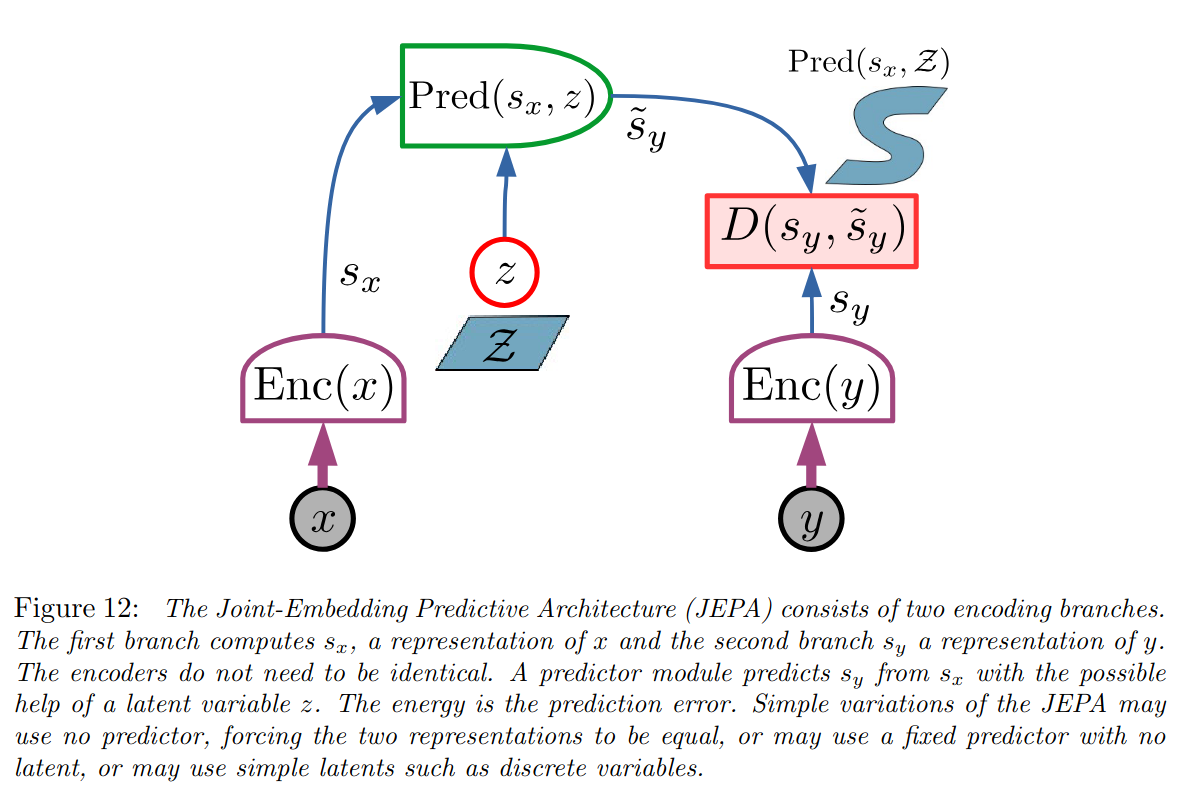
This is far from being something entirely new. Far from it, what LeCun was proposing was a generalization of many different self-supervised learning mechanisms. From SimSiam (PDF), to BYOL (PDF), many self-supervised objectives for vision can be cast under this umbrella. Recently, LeCun himself has worked on several papers that implicitly try to be instantiations of the JEPA idea, such as VICReg or BarlowTwins (PDF).
Last year we finally go to see the first implementation of this theoretical idea in the form of I-JEPA.
I-JEPA
I-JEPA has been the first work to explicitly instantiate a JEPA architecture for image self-supervised training. The idea is clear: we want to reconstruct missing parts of the input to force the network to learn relevant patterns in the data in order to solve the task. Now, this is different from the traditional inpainting because of the granularity that transformers provide. As short self-quote from “Video Transformers: A survey.”:
MTM [(Masked Token Modeling)] could be seen from the lens of generative-based pre-training as it bears great resemblance with CNN-based inpainting. We believe that the success of MTM may be attributable to Transformers providing explicit granularity through tokenization. In order to conquer the complex global task of inpainting large missing areas of the input, MTM divides it into smaller local predictions. […] Intuitively, the model needs an understanding of both global appearance […] as well as low-level local patterns to properly gather the necessary context to solve token-wise predictions. This may allow VTs to learn more holistic representations (i.e. better learning of part-whole relationships).
Also, although it had already been done for Transformers (e.g., MAE or SimMIM), the key novelty with regards to that is that here the predictions are done in feature space (instead of pixel space or HOG features, respectively) by leveraging a siamese network that will produce complete input representations.
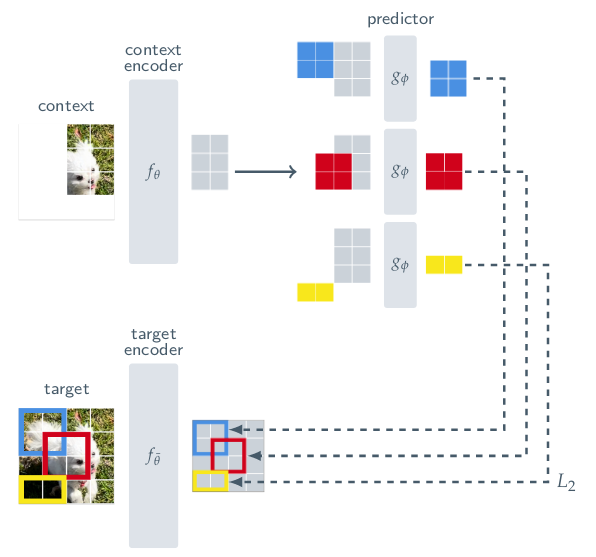
Core concept
They use two networks, the target encoder and the context encoder (plus a predictor to map representations between the two). From a given input image divided into patches, some of these are selected to be the target. From the remaining bits of the image, multiple blocks are selected to be used as context. The network is tasked with solving a predictive task: from each context block predict the target block.

Key ideas
- Split the image into tokens. Feed all of them to a target network and produce a contextualized representation for each token. Select some potentially overlaping blocks (groups of tokens) to be defined as a target.
- Next, take the input again and select multiple context blocks. None of the context blocks overlap with the target block, in order to avoid trivial solutions where the network simply forwards input information to the output. Now run individually each context block through the context network to get a representation of that portion of the input.
- Each context’s representation is then fed into a predictor network, conditioned on the target position within the image, which is tasked with reconstructing the target representation given the context.
- To avoid collapse they use asymetries and condition the prediction on the positions that are requested to be predicted (by using as input the PE learned for that position).
- Both networks share the same architecture and initialization, but only the context network is trained through backpropagation (L2 loss), and the target one only updates its weights by an exponential moving average (which seems to be key for these types of settings).
- “JEPAs do not seek representations invariant to a set of hand-crafted data augmentations, but instead seek representations that are predictive of each other when conditioned on additional information z”
- No need to use data augmentation, as they are very expensive (specially in some modalities such as video). This is true, not many methods of this type are brave enough to entirely remove data augmentation from their pipeline, even when the core of their models is these types of syamese architectures. Note that, for me, cropping and resizing is data augmentation. For instance, in SimCLR a list of data-augmentation operations is present, including crops. Still, it holds that cropping is very cheap compared to other augmentations where you need to alter pixel values (color jittering, black and white, gaussian filters, etc.). Still, it is notable that their model is working with just a few views. I think one key point for this to work is that they are not trying to make representations invariant to perturbations (as contrastive methods do), but to make the representations of partial views of an input predictable from each other.
- Instead of learning invariances to specific perturbations, it makes the views predictive of each other, making them context-dependent. In this sense, it is making different parts of the input “aware” of each other by making the output representations be predictable from the others. In other words, it is forcing the representations of a given contextual block to contain enough information to predict the context sorounding it.
- To avoid shorcut solutions, one must mask big portions of the image: “masking strategy; specifically, it is crucial to (a) sample target blocks with sufficiently large scale (semantic), and to (b) use a sufficiently informative (spatially distributed) context block”
Results
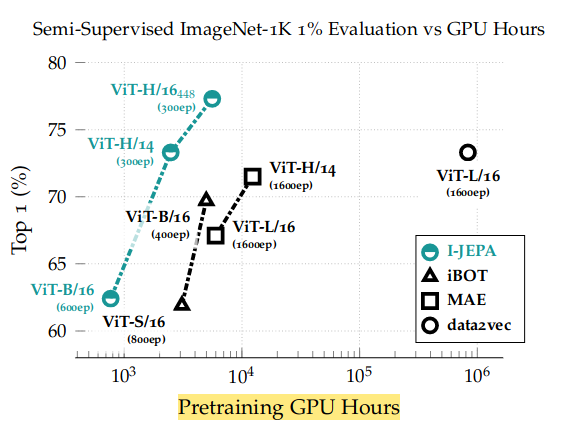
When taking a look at the results one thing kept striking me as odd. Despite the results being very competitive with previous works (both using data augmentation and not), in most cases the core architectures used are different, mostly with regards to the number of parameters. I-JEPA tends to outperform other works, specially when using the large ViT-H, larger input resolution, or smaller patch sizes. The address this claim in the scaling section, by stating that, despite their model being slightly slower than other variants, it was still faster than using data augmentation, and, furthermore, I-JEPA seems to be converging way faster. This is what allowed them to train bigger models, which for other training methods may be unfeasible.
In summary they show competitive results: in linear probing, transfer to other datasets and few-shot linear probing, with the benefit of converging faster. They show specially promising results for low level taks, showing the benefits of using local-global predictive tasks instead of contrastive methods for these tasks. This is further reinforced by MAE being the king in these tasks, a model which actually reconstructs the output at pixel level during training.
It is also interesting to check the final section where they generate the predicted context representations, showing that indeed the model has learned semantically significant features.


Javier Selva has a background of computer science and currently specializes in Machine Learning. In particular he is passionate about NLP, CV and self-supervised learning with Transformers.